note: a lot of this is based off of jim fan's talk on robotics' endgame.
modeling
world action models (WAMs) serve as the next step from vision-language-action models (VLAs), as they're able to leverage video generation + world models. one notable example of WAMs is dreamzero from nvidia's gear lab.
dreamzero is able to zero-shot tasks by jointly decoding both next world state and next actions. so if video prediction works, the action works. and if it fails, the action fails as well. as jim fan puts it, it's the "first step towards open-ended, open-vocab prompting for robotics."
VLAs on the other hand, such as $\pi_{0.7}$ from physical intelligence, are trained on static image-text pairs. thus, they inherently lack an understanding of physical causality or principles of physics and must learn the dynamics of how the world works through massive amounts of data.
however, WAMs, as mentioned earlier, are built on vidgen models such as cosmos. since the backbone is trained to predict the next frame in a video, it already understands these physical dynamics of the world and spatiotemporal transitions before it's ever deployed on a robot.
however, WAMs aren't great with new camera viewpoints or different robot starting positions, as vidgen pretraining doesn't necessarily teach something known as "3d spatial consistency" if the camera angle is completely new to the model. here, VLAs do really well. WAMs are much more robust to factors such as lighting changes, camera noise, and clutter, since they can denoise the environment around them because their pretraining involved seeing countless hours of diverse videos.
put simply, WAMs are better with visual interaction, while VLAs are really good with geometrics. with little robot data, WAMs are ideal, which achieve SOTA for robustness on visual environments. for tasks that require high-frequency control, go with VLAs because WAMs are fundamentally too slow without aggressive optimizations that don't come out the box.
data, level 1
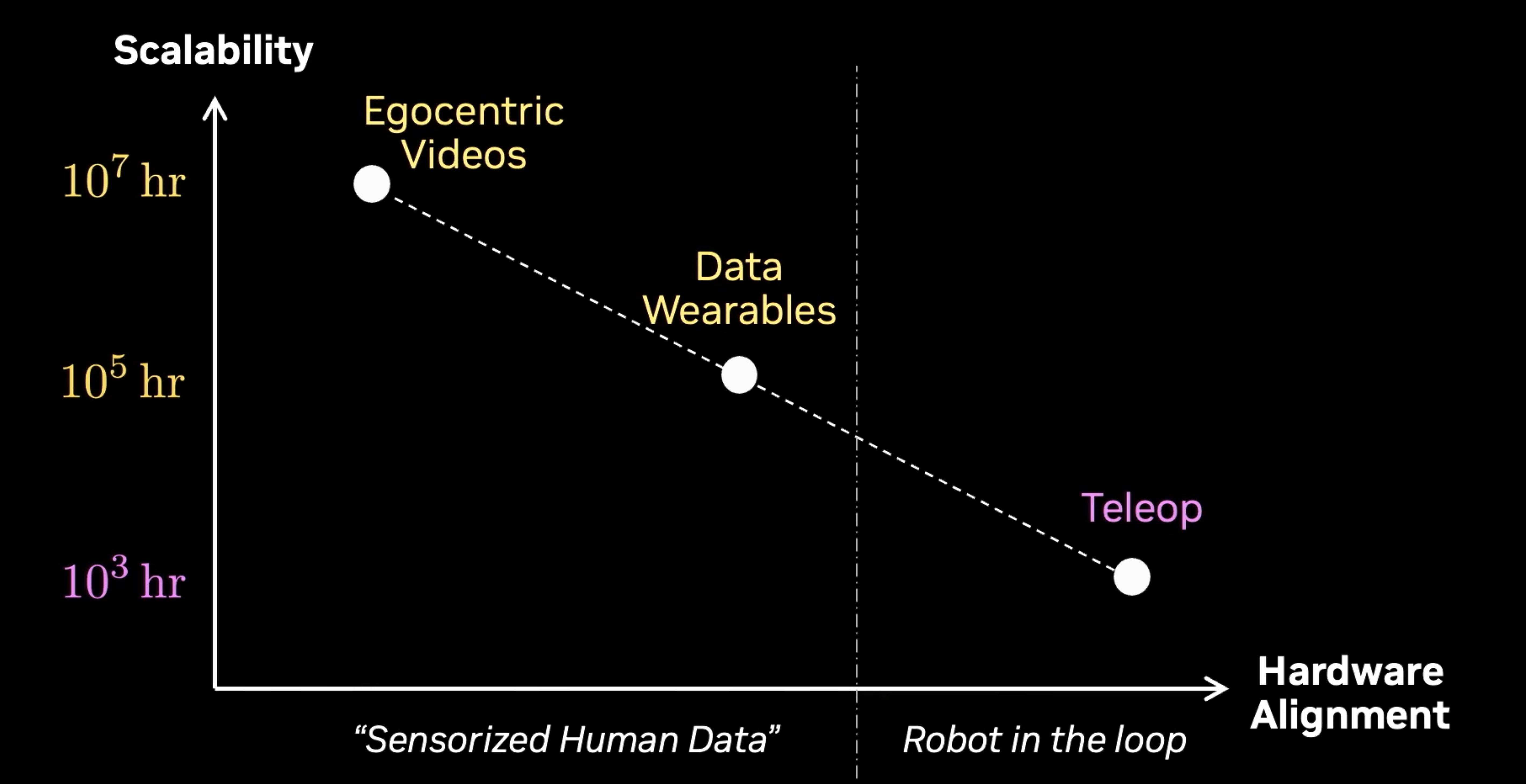
teleoperation is tough to scale, since we're bounded by the reality of only having 24 hrs a day, and only a subset of the training data being collected may be usable.
alternatively, a method that utilizes universal manipulation interfaces (UMI) allows for operators to use the robot actuators to perform tasks, and collect data from them.
that raises the question — does removing robots from the data collection loop solve scaling for robotics?
not quite. take tesla's fsd for example. users in their car contribute to a massive dataset while driving, but the difference is that it seems effortless, as the collection happens in the background. for robotics, that translates to human ego-centric videos.
we take these videos, and during pre-training, predict the hand joints and wrist poses from the videos. this coupled with action fine-tuning alongside teleop and UMI data, leads to really incredible one-shot performances by the robot.
data, level 2
the next step to augmenting robot data is to scale up environments for physical rl. this helps with continuous execution on tasks + full completions. but again, this is with the robot in the loop, which scales linearly.
on the other hand, if we take some iphone picture and pass it through a world model pipeline + classical physics simulator, we can then augment these images to different scenes. so the iphone becomes a real2sim2real transfer mechanism, relying on classical graphics engines.
however, the dreamdojo paper introduces a new approach that takes video world models and turns them into neural simulators. at a high level, these take in action signals and outputs rgb frames + sensor states in real time.
to explain it in more detail, these action signals being used are continuous latent actions$^{[1]}$, where the model looks at frame A and frame B and asks itself — what is the compressed vector that represents the delta between the two frames? as a result, the model is able to learn a universal language of movement that isn't tied to a human hand or robot arm, but rather, an understanding of physics in how pixels move.
so when we want the robot to perform some task, we don't ask it for just one output. we use the world model to perform model-based planning, where the model imagines multiple potential futures in parallel (e.g. "what if i move the arm left" vs. "what if i move the arm right"). for each of these sequences, the model generates the future rgb frames and latent states, or the model's internal representation of the environment it's been given.
dreamdojo then includes a value model that looks at these imagined futures and gives them a score based on how close they are to completing the task at hand. finally, the system selects the imagined sequence with the highest score, and executes by taking the first action from the highest-score sequence and sends it to the robot's motors to follow. the generated rgb frames are essentially a sanity check for the robot to follow.
formalized, the new post-training paradigms for WAMs looks something like:
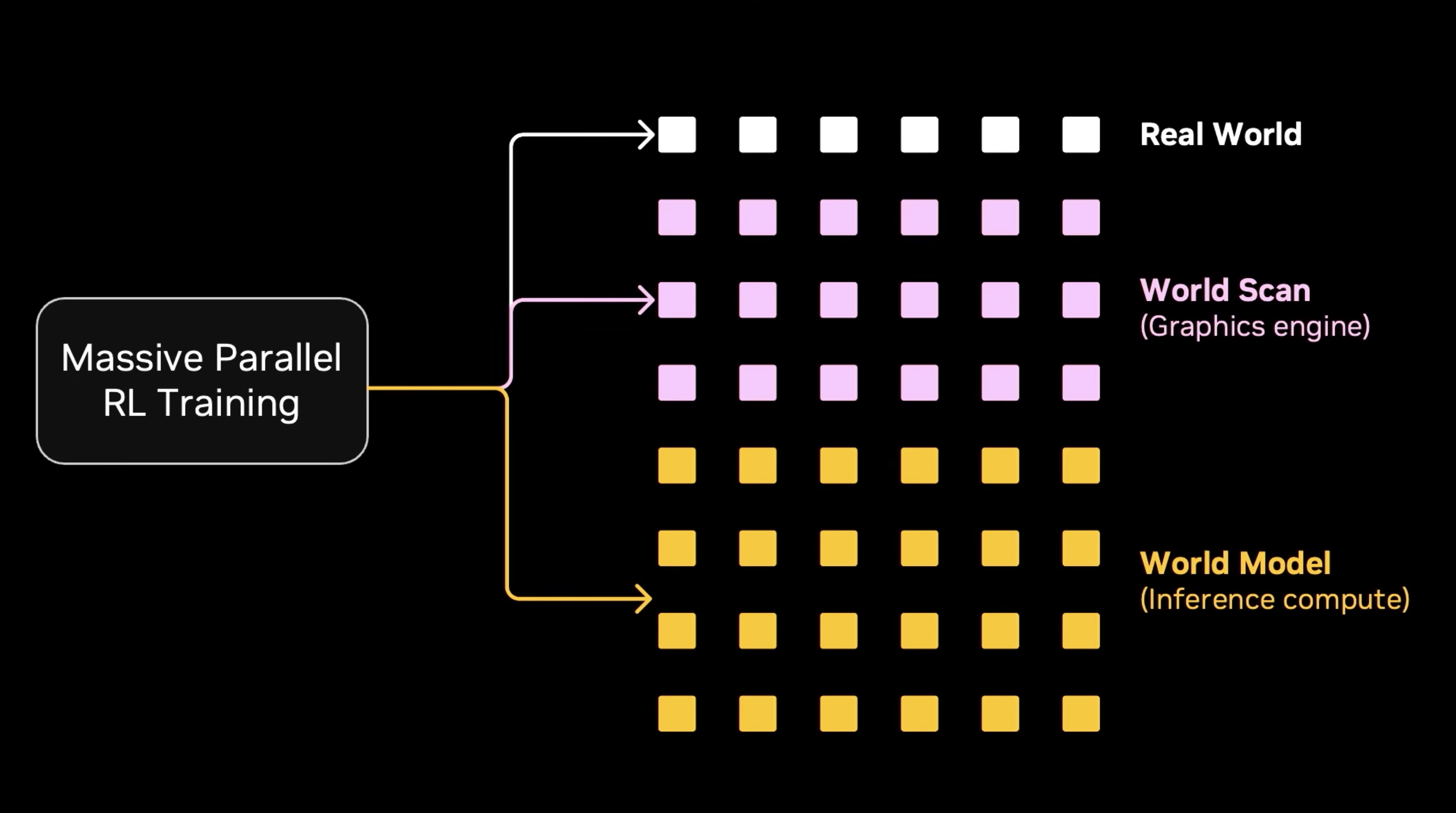
for robotics, the parallel with llms' trajectory is essentially: world modeling -> action fine-tuning -> physical rl.
and soon enough, we'll be in the endgame for robotics, simultaneously unlocking so many applications.
some questions i'll end off on:
- how can we know that these models actually understand physics + causal dynamics? alternatively, can these models generalize these principles beyond the training distribution?
- how can we couple the video-pretrained physical intuition and geometric grounding in the same model? (i.e. combining the benefits of WAMs and VLAs)
$[1]$ the reason continuous latent actions are so powerful is that they're essentially "universal," in that they decouple the action space from the embodiment entirely, which means that the same world model could theoretically plan for a humanoids, drones, aircraft, cars, etc. without retraining the dynamics backbone, allowing us to advance physical intelligence even further.
sources:
- jim fan's "robotics' end game" talk from sequoia's ai ascent: https://youtu.be/3Y8aq_ofEVs
- dreamdojo paper: https://arxiv.org/abs/2602.06949